
Here at Lynchpin, we’ve found dbt to be an excellent tool for the transformation layer of our data pipelines. We’ve used both dbt Cloud and dbt Core, mostly on the BigQuery and Postgres adapters.
We’ve found developing dbt data pipelines to be a really clean experience, allowing you to get rid of a lot of boilerplate or repetitive code (which is so often the case writing SQL pipelines!).
It also comes with some really nice bonuses like automatic documentation and testing along with fantastic integrations with tooling like SQLFluff and the VSCode dbt Power User extension.
As with everything, as we’ve used the tool more, we have found a few counter-intuitive quirks that left us scratching our heads a little bit, so we’d thought we share our experiences!
All of these quirks have workarounds, so we’ll share our thoughts plus the workarounds that we use.
Summary:
- Incremental loads don’t work nicely with wildcard table queries in BigQuery
- The sql_header() macro is the only way to do lots of essential things and isn’t really fit for purpose.
- Configuring dev and prod environments can be a bit of a pain
1. Incremental loads with wildcard tables in BigQuery
Incremental loads in dbt are a really useful feature that allows you to cut down on the amount of source data a model needs to process. At the cost of some extra complexity, they can vastly reduce query size and the cost of the pipeline run.
For those who haven’t used it, this is controlled through the is_incremental() macro, meaning you can write super efficient models like this.
SELECT *
FROM my_date_partitioned_table
{% if is_incremental() %}
WHERE date_column > (SELECT MAX(date_column) FROM {{ this }}
{% endif %}
This statement is looking at the underlying model and finding the most recent data based on date_column. It then only queries the source data for data after this. If the table my_date_partitioned_table is partitioned on date_column, then this can have massive savings on query costs.
Here at Lynchpin, we’re often working with the GA4 → BigQuery data export. This free feature loads a new BigQuery table events_yyyymmdd every day. You can query all the daily export tables with a wildcard * and also filter on the tables in the query using the pseudo-column _TABLE_SUFFIX
SELECT * FROM `lynchpin-marketing.analytics_262556649.events_*` WHERE _TABLE_SUFFIX = '20240416';
The problem is incremental loads just don’t work very nicely with these wildcard tables – at least not in the same way as a partitioned table in the earlier example.
-- This performs a full scan of every table - rendering
-- incremental load logic completely useless!
SELECT *,
_TABLE_SUFFIX as source_table_suffix
FROM `lynchpin-marketing.analytics_262556649.events_*`
{% if is_incremental() %}
WHERE _TABLE_SUFFIX > (SELECT MAX(source_table_suffix) FROM {{ this }}
{% endif %}
This is pretty disastrous because scanning every daily table in a GA4 export can be an expensive query, and running this every time you load the model doesn’t have great consequences for your cloud budget 💰.
The reason this happens is down to a quirk in the query optimiser in BigQuery – we have a full explanation and solution to it at the end of this blog 👇 if you want to fix this yourself.
2. You have to rely on the sql_header() macro quite a lot
The sql_header() macro is used to run SQL statements before the code block of your model runs, and we’ve actually found it to be necessary in the majority of our models. For instance, you need it for user defined functions, declaring and setting script variables, and for the solution to quirk #1.
The problem is that sql_header() macro isn’t really fit for purpose and you run into a few issues:
- You can’t use macros or Jinja inside sql_header() as it can lead to weird or erroneous behaviour, so no using ref, source or is_incremental() for example
- You can’t include your sql_header() configurations in tests, currently meaning any temporary functions created can’t be recreated in test cases
3. There are a few workarounds needed to truly support a dev and prod environment
dbt supports different environments, which can be easily switched at runtime using the —target command line flag. This is great for keeping a clean development environment separate from production.
One thing we did find a little annoying was configuring different data sources for your development and production runs, as you probably don’t want to have to run on all your prod data every time you run your pipeline in dev. Even if you have incremental loads set up, a change to a table schema soon means you need to run a full refresh which can get expensive if running on production data.
One solution is reducing amount of data using a conditional like so:
{% if target.name == 'dev' %}
AND date_column BETWEEN
TIMESTAMP('{{ var("dev_data_start_date") }}')
AND TIMESTAMP('{{ var("dev_data_end_date") }}')
{% endif %}
This brings in extra complexity to your codebase and is annoying to do for every single one of your models that query a source.
The best solution we saw to this was here: https://discourse.getdbt.com/t/how-do-i-specify-a-different-schema-for-my-source-at-run-time/561/3
The solution is to create a dev version of each source in the yaml file, called {model name_source}_dev (e.g. my_source_dev for the dev version of my_source) and then have a macro that switches which source based on the target value at runtime.
Another example in this vein is getting dbt to enforce foreign key constraints requires this slightly ugly expression switching between schemas in the schema.yaml file
- type: foreign_key
columns: ["blog_id"]
expression: "`lynchpin-marketing.{ 'ga4_reporting_pipeline' if target.name!='dev' else 'ga4_reporting_pipeline_dev' }}.blogs` (blogs)"
Explanation and solution to quirk #1
Let’s revisit
SELECT * FROM `lynchpin-marketing.analytics_262556649.events_*` WHERE _TABLE_SUFFIX = '20240416';
This is fine – the table scan performed here only scans tables with suffix equal to 20240416 (i.e. one table), and bytes billed is 225 KB
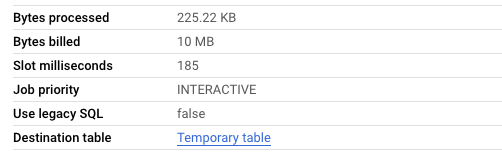
OK, so how about only wanting to query from the latest table?
If we firstly wanted to find out the latest table in the export:
-- At time of query, returns '20240416' SELECT MAX(_TABLE_SUFFIX) FROM `lynchpin-marketing.analytics_262556649.events_*`
This query actually has no cost!
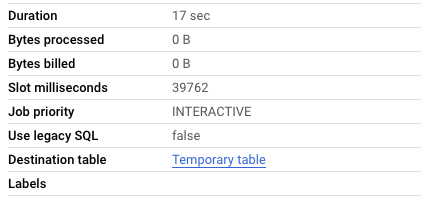
Great, so we’ll just put that together in one query:
SELECT * FROM `lynchpin-marketing.analytics_262556649.events_*` WHERE _TABLE_SUFFIX = ( SELECT MAX(_TABLE_SUFFIX) FROM `lynchpin-marketing.analytics_262556649.events_*`)
Hang on… what!?
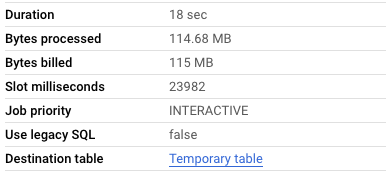
BigQuery’s query optimiser isn’t smart enough to get the value of the inner query first and use that to reduce the scope of tables queried in the outer query 😟
Here’s our solution, which involves a slightly hacky way to ensure the header works in both incremental and non-incremental loads. We implemented this in a macro to make it reusable.
{% call set_sql_header(config) %}
DECLARE table_size INT64;
DECLARE max_table_suffix STRING;
SET table_size = (SELECT size_bytes FROM {{ this.dataset }}.__TABLES__ WHERE table_id='{{ this.table }}');
IF table_size > 0 THEN SET max_table_suffix = (select MAX(max_table_suffix) FROM {{ this }});
ELSE SET max_date = '{{ var("start_date") }}';
END IF;
{% endcall %}
-- Allows for using max_table_suffix to filter source data.
-- Example usage:
SELECT
*
FROM {{ source('ga4_export', 'events') }}
{% if is_incremental() %}
WHERE _table_suffix > max_table_suffix
{% endif %}
We hope you found this blog useful. If you happen to use any of our solutions or come across any strange quirks yourself, we’d be keen to hear more!
To find out how Lynchpin can support you with data transformation, data pipelines, or any other measurement challenges, please visit our links below or reach out to a member of our team.

